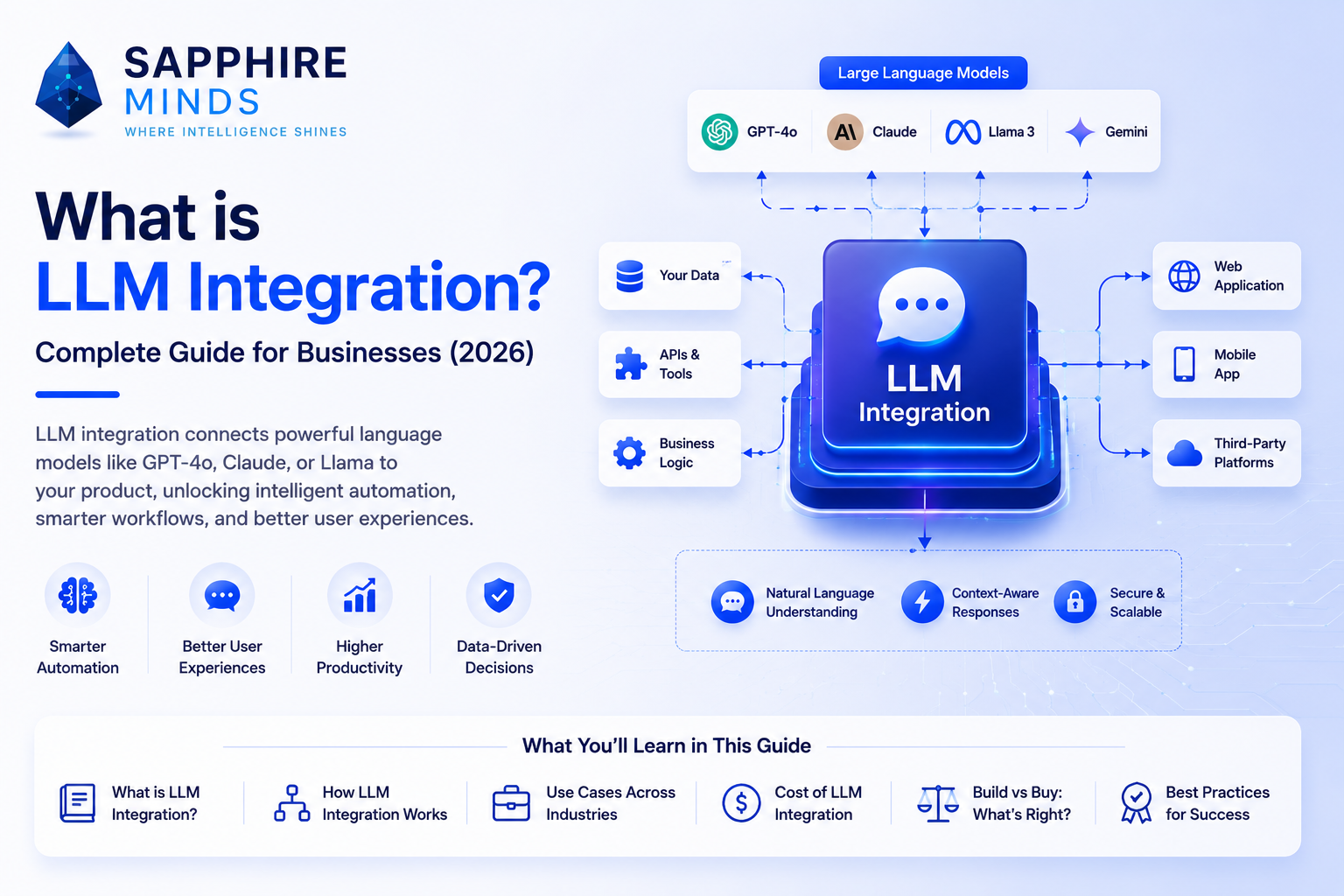
LLM integration means connecting a large language model — like Open Ai's GPT-4o, Anthropic's Claude, or Google's Gemini — to your application so it can understand language, generate content, answer questions, or automate tasks on behalf of your users.
In 2026, LLM integration has shifted from experimental to essential. Products without at least one AI-powered feature are increasingly losing ground to competitors who have them.
How LLM integration actually works
At its core, every LLM integration follows the same pattern:
1. Your application sends a text prompt to the LLM via API
2. The LLM processes the prompt and returns a text response
3. Your application uses that response - displays it, stores it, or acts on it
The complexity is in everything around that core loop: what goes into the prompt, how you handle the response, how you manage costs, and how you make it reliable at scale.
The three types of LLM integration
Type 1 — Direct API calls (simplest)
Your backend calls the LLM API with a user's input and returns the response. Best for: single-turn features like "summarize this", "improve this text", or "answer this question".
```
User input → Your backend → LLM API → Response → User
```
Timeline to build: 1-3 days for a basic implementation.
Type 2 — RAG (Retrieval Augmented Generation)
Before calling the LLM, you retrieve relevant content from your own data — documents, database records, knowledge base - and include it in the prompt as context. The LLM then answers based on your specific data, not just its training.
```
User question → Embed question → Search vector database
→ Retrieve relevant chunks → Build prompt with context
→ LLM API → Accurate, grounded answer
```
Best for: support bots that know your product, search over your documentation, Q&A over uploaded documents. Timeline: 2-4 weeks for production-ready implementation.
Type 3 — AI Agents
The LLM can call tools - search the web, query a database, send an email, run code - to complete multi-step tasks autonomously. The model decides which tools to use and in what order.
Best for: complex automation workflows, intelligent process orchestration. Still emerging in terms of production reliability, but increasingly viable in 2026.
Which LLM should you integrate?
| Model | Best use case | Cost (approx.) |
|---|---|---|
| GPT-4o (Open AI) | General purpose, best reasoning quality | $2.50/1M input tokens |
| GPT-4o mini | High volume, simpler tasks | $0.15/1M input tokens |
| Claude 3.5 Sonnet | Long documents, nuanced analysis | Similar to GPT-4o |
| Gemini 1.5 Pro | Very long context (1M tokens), multimodal | Competitive |
| Llama 3 (open source) | Self-hosted, cost control at scale | Infrastructure cost only |
Practical rule: Start with GPT-4o mini for cost efficiency. Use GPT-4o or Claude 3.5 for tasks requiring deeper reasoning. Abstract your LLM calls behind a service layer so you can swap providers without rewriting your application.
What you can build with LLM integration
For SaaS products:
- Smart search — users search in natural language, results are semantic not keyword-based
- Document intelligence — upload a contract, PDF, or report and ask questions about it
- Content generation — "write this for me", "improve this", "translate this"
- Automated summaries — long support tickets, meeting notes, reports summarized automatically
- AI chatbots — support assistants, onboarding guides, internal knowledge bases
- Auto-classification — tickets, leads, and support requests categorized automatically
For internal tools:
- Workflow automation — route, classify, and action incoming data without manual review
- Report generation — natural language summaries of business data
- Employee assistants — answer questions from internal documentation
LLM integration cost planning
The most common mistake is building without planning for ongoing API costs.
Sample calculation:
- 5,000 monthly active users
- Each user triggers 5 LLM calls per session
- Average 800 tokens per call (input + output combined)
- 5,000 × 5 × 800 = 20 million tokens/month
At GPT-4o mini pricing ($0.15/1M input, $0.60/1M output, assuming 50/50 split):
- ~$3.75/month input + ~$3.00/month output = ~$7/month total
At GPT-4o pricing ($2.50/$10.00):
- ~$62.50 + ~$50 = ~$112.50/month
Cost control strategies:
- Use GPT-4o mini for high-volume simple tasks
- Cache responses for identical or near-identical prompts
- Set max_tokens to cap response length
- Monitor per-user API spend from day one
What makes LLM integration production-ready
A demo-quality integration and a production-quality integration are very different things. Production requires:
Error handling: LLM APIs can return errors, timeouts, or unexpected responses. Every integration needs graceful fallbacks.
Rate limiting: Protect your Open AI spend by limiting how many LLM calls any single user can make.
Streaming: Use Server-Sent Events to stream tokens to the frontend in real time. Users see responses appearing word by word rather than waiting for the full response — dramatically better UX.
Cost monitoring: Build dashboards showing API spend per feature, per user, per day before you need them.
Prompt security: Sanitize user inputs. Without it, users can attempt prompt injection — feeding instructions into the prompt to make the model behave unexpectedly.
When to build vs buy
Buy (use an off-the-shelf tool) when:
- Your use case is generic (basic chatbot, simple Q&A)
- Off-the-shelf tools like Intercom Fin solve it adequately
- Speed to market matters more than customization
Build (custom LLM integration) when:
- The AI feature is core to your product's value proposition
- You need the AI to understand your specific data or domain
- You need control over cost, behavior, and user experience
- You're building at a scale where per-seat SaaS costs become prohibitive
Building your LLM integration with Sapphire Minds
Sapphire Minds specializes in production-grade LLM integrations - from single AI features to full AI-native products. We've built RAG pipelines, AI chatbots, document intelligence systems, and generative AI features for SaaS products across multiple industries.
If you're planning an LLM integration and want to understand the architecture, cost, and timeline for your specific use case